【机器学习】防止过拟合的方法
什么是过拟合
从训练样本中尽可能学出适用于所有潜在样本的“普遍规律”,这样才能在遇到新样本时做出正确的判别。然而,当学习器把训练样本学得“太好”了的时候,很可能已经把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,这样就会导致泛化性能下降。这种现象在机器学习中称为“过拟合”(overfitting)。
与过拟合相对的是“欠拟合”(underfitting),这是指对训练样本的一般性质尚未学好。
过拟合产生的原因
- 训练数据量的限制
- 训练参数的增多
- 学习能力过于强大(由学习算法和数据内涵共同决定)
防止过拟合的方法
- 数据增强(data augmentation):一般想要获得更好的模型,需要大量的训练参数,这也是为什么CNN网络越来越深的原因之一,而如果训练样本缺乏多样性,那再多的训练参数也毫无意义,因为这造成了过拟合,训练模型的泛化能力相应也会很差。大量数据带来的特征多样性有助于充分利用所有的训练参数。办法一般有:(1)收集更多的数据 (2)对已有的数据进行修剪(crop),翻动(flip),加光照等(3)利用生成模型(比如GAN)生成一些数据。
- 权重衰减(weight decay):常用的权重衰减有L1和L2正则化,L1较L2能够获得更稀疏的参数,但L1零点不可导。在损失函数中,权重衰减是放在正则项(regulation)前面的一个系数,正则项一般指示模型的复杂度,所以权重衰减的作用是调节模型复杂度对损失函数的影响,若权重衰减很大,则复杂的模型损失函数的值也就大。
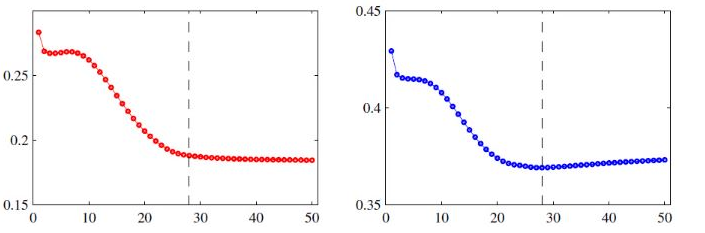
- 提前终止:提前终止其实是另一种正则化方法,就是在训练集和验证集上,一次迭代之后计算各自的错误率,当在验证集上的错误率最小,在没开始增大之前就停止训练,因为如果接着训练,训练集上的错误率一般是会继续减小的,但验证集上的错误率会上升,这就说明模型的泛化能力开始变差了,出现过拟合问题,及时停止能获得泛化能力更好的模型。如下图(左图是训练集错误率,右图是验证集错误率,在虚线处提前结束训练):
- 退出(dropout):CNN训练过程中使用dropout是在每次训练中随机将部分神经元的权重置为0,即让一些神经元失效,这样可以缩减参数量,避免过拟合。原因在于:(1)每次迭代随机使部分神经元失效,使得模型的多样性增强,获得了类似于多个模型组合(ensemble,合唱)的效果,避免过拟合;(2)dropout其实也是一个数据增强的过程,它导致了稀疏性,使得局部数据簇差异性明显增强,有效避免过拟合。
参考资料
- 周志华.《机器学习》.清华大学出版社.第2章-模型评估与选择.
- https://blog.csdn.net/leo_xu06/article/details/71320727 卷积神经网络(CNN)防止过拟合的方法.
- Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]// International Conference on Neural Information Processing Systems. Curran Associates Inc. 2012:1097-1105.
【机器学习】防止过拟合的方法
https://xiepeng21.cn/posts/3634e5b5/